
در عصر پساکوکی و با افزایش محدودیتهای سختگیرانه بر ردیابی کاربران در پلتفرمهای شخص ثالث، تکیه بر دادههای اجارهای نه تنها ریسک عملیاتی بالایی دارد، بلکه مانع اصلی در مسیر پیادهسازی شخصیسازی واقعی با هوش مصنوعی است. کسبوکارهایی که به دنبال ایجاد سیستمهای رشد خودمختار هستند، باید از رویکرد سنتی ذخیرهسازی ایستا عبور کرده و به سمت طراحی یک سیستم عصبی زنده حرکت کنند. معماری دادههای دست اول در این چارچوب، صرفاً یک مخزن برای نگهداری اطلاعات نیست، بلکه یک خط لوله سوخترسانی مهندسیشده است که سیگنالهای رفتاری خام را به ورودیهای تصمیمساز برای مدلهای یادگیری ماشین تبدیل میکند. بدون این زیرساخت اختصاصی، موتورهای هوش مصنوعی سازمان در خلاء فعالیت کرده و خروجیهای آنها فاقد دقت لازم برای اثرگذاری بر تجربه کاربر در لحظه خواهد بود.
پارادایم جدید در مدیریت داده: از ذخیرهسازی تا مهندسی تصمیم
رویکرد سنتی به دادههای مشتری اغلب بر جمعآوری حداکثری و ذخیره در پایگاههای داده رابطهای متمرکز بود. در این مدل، دادهها به صورت تودهای و در بازههای زمانی مشخص پردازش میشدند که منجر به ایجاد فاصله زمانی میان رفتار کاربر و واکنش سیستم میشد. در مقابل، معماری دادههای دست اول در سیستمهای هوشمند امروزی بر پایه مهندسی تصمیم بنا شده است. در این دیدگاه، هر تعامل کاربر یک رویداد تلقی میشود که باید در لحظه تحلیل شده و به یک سیگنال معنادار تبدیل گردد. هدف اصلی در مهندسی تصمیم، کاهش فاصله زمانی میان دریافت داده و اتخاذ کنش است.
وقتی یک کاربر در یک پلتفرم دیجیتال جابهجا میشود، معماری سیستم باید بتواند این الگوهای رفتاری را با دادههای تاریخی ترکیب کرده و پروفایل لحظهای کاربر را بهروزرسانی کند. این سطح از بلوغ فنی نیازمند تغییر ساختار از پایگاههای داده ایستا به محیطهای دادهای پویا است که در آن جریان داده هرگز متوقف نمیشود. مهندسی تصمیم به معنای طراحی زیرساختی است که در آن دادهها بلافاصله پس از تولید، برای استفاده در مدلهای پیشبینیکننده آمادهسازی میشوند. این آمادگی شامل پاکسازی، غنیسازی و نگاشت دادهها به ویژگیهای مورد نیاز هوش مصنوعی است.
انتقال به این پارادایم مستلزم درک این واقعیت است که ارزش داده در سرعت تبدیل آن به اقدام نهفته است. در معماریهای سنتی، دادهها ساعتها یا روزها در صف پردازش میماندند، اما در سیستمهای مدرن مبتنی بر هوش مصنوعی، ارزش یک سیگنال رفتاری پس از گذشت چند دقیقه به شدت افت میکند. بنابراین، معماری دادههای دست اول باید به گونهای طراحی شود که کمترین میزان تأخیر را در چرخه حیات داده داشته باشد.
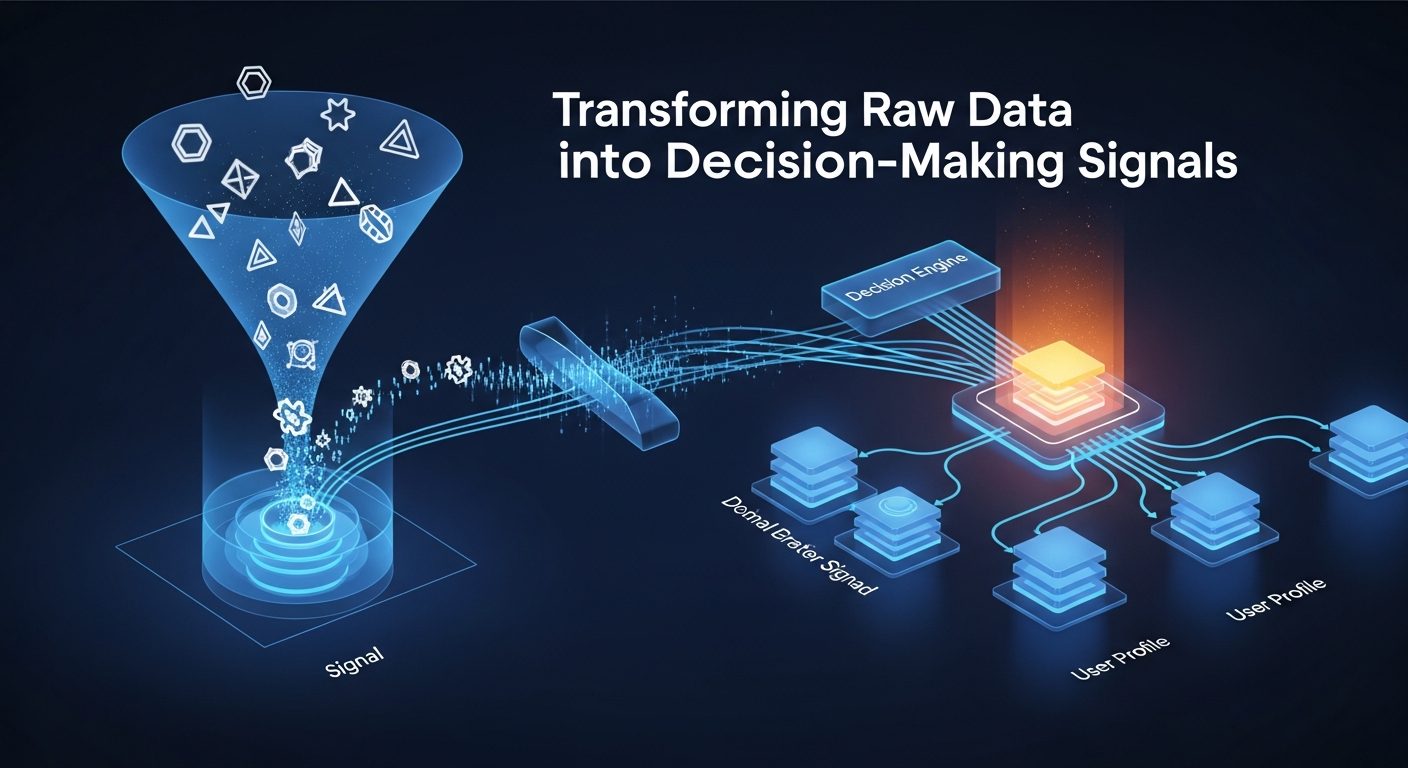
کالبدشکافی فنی لایههای معماری داده برای هوش مصنوعی
یک معماری استاندارد و مقیاسپذیر برای دادههای اختصاصی از چندین لایه متصلبههم تشکیل شده است که هر کدام وظیفه خاصی در چرخه حیات داده بر عهده دارند. هماهنگی این لایهها تضمین میکند که هوش مصنوعی همیشه به تازهترین و مرتبطترین اطلاعات دسترسی دارد.
لایه جمعآوری و استخراج سیگنالهای رفتاری
اولین مرحله در معماری دادههای دست اول، طراحی سازوکارهای دقیق برای رهگیری تعاملات است. این لایه شامل کیتهای توسعه نرمافزار اختصاصی و رابطهای برنامهنویسی است که نه تنها تراکنشهای نهایی، بلکه سیگنالهای پیشتراکنشی مانند مدت زمان توقف روی یک بخش، مسیر حرکت کاربر در اپلیکیشن و ترتیب بازدید از محصولات را ثبت میکنند.
تفاوت اصلی در اینجا، کیفیت و ساختاریافتگی دادهها در مبدأ است. دادههایی که در لایه جمعآوری به درستی برچسبگذاری نشده باشند، در مراحل بعدی هزینههای پردازشی سنگینی را برای پاکسازی به سیستم تحمیل میکنند. در این لایه، استفاده از جمعآوری داده در سمت سرور به جای سمت کلاینت ترجیح داده میشود تا دقت دادهها افزایش یافته و محدودیتهای مرورگرها و مسدودکنندههای تبلیغاتی دور زده شود.
لایه پردازش جریان و غنیسازی لحظهای
دادههای خام به تنهایی برای مدلهای شخصیسازی هوش مصنوعی کارایی ندارند. لایه پردازش جریان وظیفه دارد دادههای ورودی را با اطلاعات موجود در انبار داده تطبیق داده و آنها را غنیسازی کند. برای مثال، اگر کاربری روی یک دسته محصول کلیک کند، سیستم باید در کمتر از چند میلیثانیه متوجه شود که آیا این کاربر قبلاً محصولات مشابهی را خریداری کرده یا در بخشبندیهای خاصی از وفاداری قرار دارد.
این پردازش لحظهای باعث میشود که ایجنتهای هوش مصنوعی بتوانند توصیههای خود را بر اساس آخرین وضعیت ذهنی کاربر تنظیم کنند. غنیسازی داده در این لایه میتواند شامل افزودن اطلاعات آبوهوایی، موقعیت جغرافیایی یا سوابق تعاملات اخیر باشد که همگی به مدل هوش مصنوعی کمک میکنند تا تصمیم دقیقتری بگیرد.
لایه ذخیرهسازی نوین و مدیریت پروفایل واحد
در معماری دادههای دست اول، مفهوم پروفایل واحد مشتری از اهمیت حیاتی برخوردار است. لایه ذخیرهسازی باید بتواند دادههای پراکنده از دستگاههای مختلف و نقاط تماس گوناگون را با یکدیگر ترکیب کرده و یک تصویر ۳۶۰ درجه از کاربر بسازد. استفاده از فناوریهای نوین مانند دریاچه داده و انبارهای داده ابری اجازه میدهد تا حجم عظیمی از دادههای ساختاریافته و غیرساختاریافته با هزینه بهینه نگهداری شوند.
در این لایه، دادهها به شکلی ذخیره میشوند که هم برای گزارشهای تحلیلی انسانی و هم برای دسترسی سریع مدلهای هوش مصنوعی مناسب باشند. تفکیک لایه ذخیرهسازی به بخشهای سرد برای دادههای تاریخی و گرم برای دادههای لحظهای، یکی از تکنیکهای مهندسی برای حفظ کارایی در مقیاسهای بزرگ است.
یکپارچهسازی هویت و حل چالش دادههای پراکنده
یکی از پیچیدهترین بخشهای معماری دادههای دست اول، شناسایی و اتصال فعالیتهای یک کاربر واحد در کانالهای مختلف است. کاربران ممکن است در طول روز از طریق گوشی هوشمند، تبلت و دسکتاپ با یک برند تعامل داشته باشند. بدون یک سیستم یکپارچهسازی هویت، هر یک از این تعاملات به عنوان یک کاربر مجزا شناسایی شده و تجربه شخصیسازیشده تخریب میشود.
معماری سیستم باید دارای یک موتور گراف هویت باشد که با استفاده از نشانگرهای مختلف مانند آدرس ایمیل، شماره تماس، شناسههای دستگاه و کوکیهای اختصاصی، این نقاط را به یکدیگر متصل کند. این فرآیند باید به صورت قطعی یا احتمالی انجام شود. در روش قطعی، از دادههای صریح مانند ورود به حساب کاربری استفاده میشود، در حالی که در روش احتمالی، مدلهای یادگیری ماشین بر اساس الگوهای رفتاری حدس میزنند که این دستگاهها متعلق به یک فرد هستند.
یکپارچگی هویت نه تنها دقت شخصیسازی را بالا میبرد، بلکه از ارسال پیامهای تکراری و متناقض به کاربر جلوگیری میکند. این لایه در معماری، زیربنای اصلی برای پیادهسازی استراتژیهای بازاریابی چندکاناله است که در آن هوش مصنوعی میداند کاربر در کدام مرحله از سفر خرید قرار دارد و بهترین پیام را در بهترین زمان و از طریق مناسبترین دستگاه ارسال میکند.
تبدیل دادههای خام به سیگنالهای تصمیمساز
هوش مصنوعی برای عملکرد بهینه به دادههایی نیاز دارد که دارای ویژگیهای آماری معنادار باشند. فرآیند تبدیل دادههای خام به سیگنالهای تصمیمساز، که در مهندسی داده با عنوان مهندسی ویژگی شناخته میشود، قلب تپنده معماری دادههای دست اول است. در این مرحله، دادههای پراکنده به متغیرهایی تبدیل میشوند که برای مدلهای پیشبینیکننده قابل فهم باشند.
به جای ذخیره ساده «تعداد بازدیدها»، سیستم باید متغیرهای پیچیدهتری مانند نرخ شتاب تعامل یا فاصله زمانی تا آخرین خرید را محاسبه کند. این سیگنالها مستقیماً به مدلهای هوش مصنوعی تغذیه میشوند تا پیشبینیهایی در مورد احتمال ریزش مشتری، ارزش طول عمر یا محصول بعدی پیشنهادی ارائه دهند. طراحی این لایه نیازمند همکاری نزدیک میان مهندسان داده و متخصصان هوش مصنوعی است تا اطمینان حاصل شود که دادههای تولید شده بیشترین تاثیر را بر دقت مدلها دارند.
یک معماری موفق در این بخش، باید قابلیت بازتولید ویژگیها را داشته باشد؛ یعنی بتواند متغیرهای مشابه را هم برای دادههای تاریخی در مرحله آموزش مدل و هم برای دادههای زنده در مرحله استنتاج تولید کند. عدم هماهنگی میان این دو حالت منجر به افت شدید عملکرد سیستم در محیط واقعی میشود.

تقابل معماریهای رویدادمحور با سیستمهای سنتی تودهای
تفاوت بنیادی میان معماری دادههای دست اول مدرن و روشهای قدیمی در نحوه برخورد با مفهوم زمان و ترتیب رویدادها است. سیستمهای سنتی بر پایه پردازش تودهای عمل میکنند؛ یعنی دادهها در طول روز جمعآوری شده و در انتهای روز پردازش میشوند. این مدل برای گزارشهای فروش ماهانه مناسب است اما برای شخصیسازی لحظهای که در آن زمان پاسخدهی به میلیثانیه اهمیت دارد، کاملاً ناکارآمد است.
در معماری رویدادمحور، هر فعالیت کاربر به عنوان یک محرک عمل میکند که بلافاصله پیامی را در کل سیستم منتشر میکند. این رویکرد به هوش مصنوعی اجازه میدهد تا در لحظهای که کاربر بیشترین تمایل به تعامل را دارد، محتوای متناسب را ارائه دهد. استفاده از تکنولوژیهای صفبندی پیام و گذرگاههای داده در این بخش از معماری، پایداری سیستم را تضمین میکند.
مزیت دیگر معماری رویدادمحور، قابلیت گسترشپذیری آن است. در این مدل، میتوان به سادگی مصرفکنندگان جدیدی برای دادهها تعریف کرد؛ برای مثال، همزمان که دادهها به مدل شخصیسازی وبسایت ارسال میشوند، میتوان آنها را به سیستم ارسال نوتیفیکیشن یا ابزار تحلیل رقابتی نیز هدایت کرد، بدون اینکه بار اضافی بر منبع تولید داده تحمیل شود.
مدیریت حریم خصوصی و امنیت در سطح لایههای زیرساختی
با افزایش اهمیت دادههای دست اول، مسئولیت سازمان در قبال حفظ امنیت و حریم خصوصی کاربران نیز به شدت افزایش یافته است. معماری سیستم باید از ابتدا با رویکرد حریم خصوصی در طراحی بنا شود. این به معنای آن است که مکانیزمهای رضایتگیری کاربران مستقیماً با لایههای جمعآوری داده یکپارچه شوند.
در یک معماری مهندسیشده، دادههای حساس باید بلافاصله پس از ورود به سیستم ناشناسسازی یا رمزنگاری شوند. همچنین، سیستم باید قادر باشد به درخواستهای کاربران مبنی بر حذف دادهها یا دسترسی به اطلاعات شخصی، به صورت خودکار و در کوتاهترین زمان پاسخ دهد. تمرکز بر دادههای دست اول به جای دادههای شخص ثالث، ذاتاً امنیت حریم خصوصی را بهبود میبخشد، زیرا سازمان کنترل کامل بر منشأ و نحوه استفاده از دادهها دارد.
امنیت در این لایه شامل مدیریت سطوح دسترسی نیز میشود. تنها مدلهای هوش مصنوعی و فرآیندهای مجاز باید به دادههای خام دسترسی داشته باشند و سایر بخشهای سازمان باید از نسخههای خلاصهسازی شده یا تجمیعی استفاده کنند. این تفکیک دسترسی، خطر نشت اطلاعات را به حداقل میرساند و اعتماد کاربران را به برند تقویت میکند.

موانع عملیاتی در پیادهسازی معماری دادههای دست اول
انتقال به یک معماری دادهمحور هوشمند با چالشهای متعددی روبرو است که فراتر از مسائل صرفاً فنی هستند. یکی از بزرگترین موانع، وجود سیلوهای داده در بخشهای مختلف سازمان است. دادههای فروش، پشتیبانی، بازاریابی و لجستیک اغلب در سیستمهای جداگانهای نگهداری میشوند که با یکدیگر ارتباط ندارند. شکستن این سیلوها و ایجاد یک جریان داده یکپارچه نیازمند تغییر در فرهنگ سازمانی و فرآیندهای کاری است.
چالش دیگر، کمبود مهارتهای فنی لازم برای مدیریت و نگهداری این سیستمهای پیچیده است. معماری دادههای دست اول نیازمند تخصص در زمینههایی مانند مهندسی داده، زیرساختهای ابری، امنیت اطلاعات و یادگیری ماشین است. سازمانها باید بر روی آموزش نیروهای داخلی یا همکاری با شرکای استراتژیک سرمایهگذاری کنند تا بتوانند از پتانسیل کامل این فناوری بهرهمند شوند.
همچنین، هزینه اولیه راهاندازی این زیرساختها میتواند قابل توجه باشد. با این حال، باید به این موضوع به عنوان یک سرمایهگذاری بلندمدت نگریست. هزینههای ناشی از عدم شخصیسازی، از دست دادن مشتریان به دلیل تجربه کاربری ضعیف و وابستگی به پلتفرمهای تبلیغاتی گرانقیمت، در درازمدت بسیار بیشتر از هزینه طراحی یک معماری اختصاصی خواهد بود.
نقشه راه گذار برای مدیران و استراتژیستها
برای پیادهسازی موفق معماری دادههای دست اول، سازمانها باید یک رویکرد مرحلهای را اتخاذ کنند. شروع با یک پروژه کوچک و متمرکز بر یک کانال خاص (مانند شخصیسازی ایمیل یا توصیهگر محصول در وبسایت) اجازه میدهد تا زیرساختهای اولیه تست شده و ارزش عملیاتی سیستم به اثبات برسد.
در مرحله اول، تمرکز باید بر حسابرسی دادههای موجود و شناسایی شکافهای اطلاعاتی باشد. سازمان باید بداند چه دادههایی را در اختیار دارد و چه سیگنالهایی برای تغذیه هوش مصنوعی کمبود دارد. در مرحله دوم، انتخاب ابزارها و تکنولوژیهای مناسب با توجه به مقیاس کسبوکاره و اهداف تجاری انجام میشود. انتخاب بین راهکارهای آماده یا توسعه سیستمهای اختصاصی یک تصمیم استراتژیک است که به بودجه و توان فنی سازمان بستگی دارد.
در مرحله نهایی، سیستم باید به صورت مداوم پایش و بهینهسازی شود. رفتار کاربران تغییر میکند و مدلهای هوش مصنوعی نیز نیاز به آموزش مجدد دارند. معماری سیستم باید به گونهای انعطافپذیر باشد که بتواند با تغییرات تکنولوژی و نیازهای بازار همگام شود.
پرسشهای متداول درباره معماری دادههای دست اول
تفاوت اصلی بین انبار داده سنتی و معماری دادههای دست اول چیست؟
انبار دادههای سنتی عمدتاً برای تحلیلهای تاریخی و گزارشدهی ایستا طراحی شدهاند و دادهها را به صورت تودهای پردازش میکنند. اما معماری دادههای دست اول برای شخصیسازی با هوش مصنوعی، بر پردازش لحظهای رویدادها و تولید سیگنالهای تصمیمساز متمرکز است تا بتواند در لحظه بر تجربه کاربر اثر بگذارد.
چگونه میتوان دقت دادههای جمعآوری شده را تضمین کرد؟
دقت دادهها از طریق جمعآوری در سمت سرور، استفاده از پروتکلهای اعتبارسنجی داده در مبدأ و پاکسازی خودکار در لایه پردازش تضمین میشود. همچنین، یکپارچهسازی هویت و حذف رکوردهای تکراری نقش مهمی در حفظ کیفیت دادهها ایفا میکند.
آیا برای شروع نیاز به حجم عظیمی از داده داریم؟
خیر، کیفیت و مرتبط بودن دادهها بسیار مهمتر از حجم آنها است. برای شروع شخصیسازی با هوش مصنوعی، داشتن دادههای رفتاری دقیق از چند نقطه تماس کلیدی کفایت میکند. با رشد سیستم، میتوان منابع دادهای بیشتری را به معماری اضافه کرد.
نقش دادههای صفر در این معماری چیست؟
دادههای صفر، اطلاعاتی هستند که کاربران به صورت داوطلبانه و صریح در اختیار برند قرار میدهند (مانند اولویتها یا علایق). این دادهها ارزشمندترین ورودی برای معماری دادههای دست اول محسوب میشوند، زیرا دارای بالاترین سطح دقت و اعتماد هستند و هوش مصنوعی میتواند از آنها به عنوان لنگری برای تفسیر سایر رفتارهای کاربر استفاده کند.
چگونه میتوان امنیت دادهها را در محیطهای ابری تامین کرد؟
امنیت از طریق رمزنگاری دادهها در حال حرکت و در حالت سکون، مدیریت دقیق دسترسیها و رعایت استانداردهای حریم خصوصی تامین میشود. معماریهای مدرن از محیطهای ایزوله ابری و خدمات امنیتی پیشرفته پلتفرمهای زیرساختی برای محافظت از داراییهای دادهای استفاده میکنند.


نظرات
نظر شما با موفقیت ارسال شد!
از اینکه نظر خود را با ما به اشتراک گذاشتید متشکریم. نظر شما پس از بررسی و تایید منتشر خواهد شد.
خطا در ارسال نظر
مشکلی پیش آمده. لطفا دوباره تلاش کنید.